728x90
Spring WebFlux 탄생 배경
Spring MVC
서블릿 기반의 Blocking I/O 방식
요청당 하나의 스레드를 사용, 스레드의 작업이 끝날 때 까지 스레드가 차단됨
Spring MVC의 한계
대용량 요청 트래픽을 Spring MVC 방식이 처리하기엔 한계가 있었다.
- 트래픽이 많아지면 많아질수록 스레드도 많이 사용되는데,
- 스레드풀에 스레드 200개가 default로 존재하고, 만약 만명이 동시 접근한다면...?
- 스레드 스위칭비용도 그만큼 많이 발생한다.
Spring WebFlux를 이용한 극복
대용량 트래픽을 감당하기 위해선, 비동기/논블로킹 방식의 I/O를 사용해야 했으며 이 방식이 적용되어, 대용량도 안정적으로 처리할 수 있는 Spring WebFlux가 생겨놨다.
** 예시를 통해 MVC와 WebFlux의 차이를 명확하게 이해해보자.**

클라이언트가 백엔드 서버로 요청을 보내면, 백엔드 서버는 외부 서버로 요청을 보내게 되는데 이때 외부 서버의 동작이 5초 걸린다고 가정하자.
클라이언트의 요청은 총 5번이 들어왔다.

MVC의 경우
MVC는 서블릿 기반 동기식 처리를 한다.
외부 서버로 요청을 보낼 때 동기 처리를 하는 RestTemplate을 사용해서 처리를 한다고 했을 때
5번(요청) * 5초(외부 서버의 응답 처리 시간) == 총 25초가 걸릴것이다.
외부 서버와 통신할 때 요청 처리 스레드는 블로킹(Blocking)된다.
WebFlux의 경우
웹 플럭스는 비동기 넌블로킹 방식의 리액티브 프로그래밍을 지원한다.
이때 외부 서버로 요청을 보내면서 WebClient를 사용하면
5번의 요청에서 블로킹이 발생하지 않는다.
무슨 의미냐 하면
** 외부 서버에서 5초 걸리는것을 우리 서버에서 기다리지 않는다는 것이다. **
블로킹이 발생해서 25초 걸렸던 MVC와 비교했을때 대용량 처리가 필요한 상황에서 아주 빠른 처리를 할 수 있다.
Spring WebFlux Stack
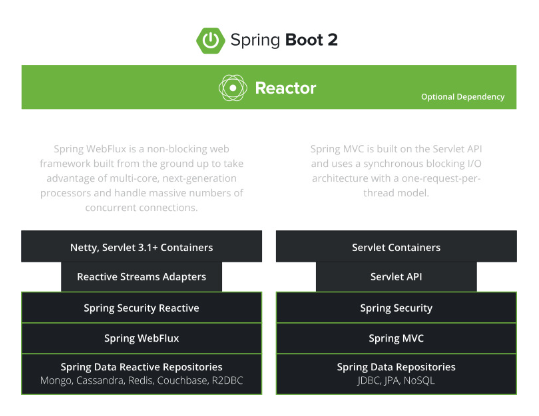
- Netty (기본 서버 엔진)
리액티브 스트림즈 어댑터를 통한, 리액티브 스트림즈 지원- WebFilter (Spring Security 사용)
- NoSQL 모듈 사용 (Spring Data R2DBC, Non-Blocking I/O 지원)
전체 큰 그림
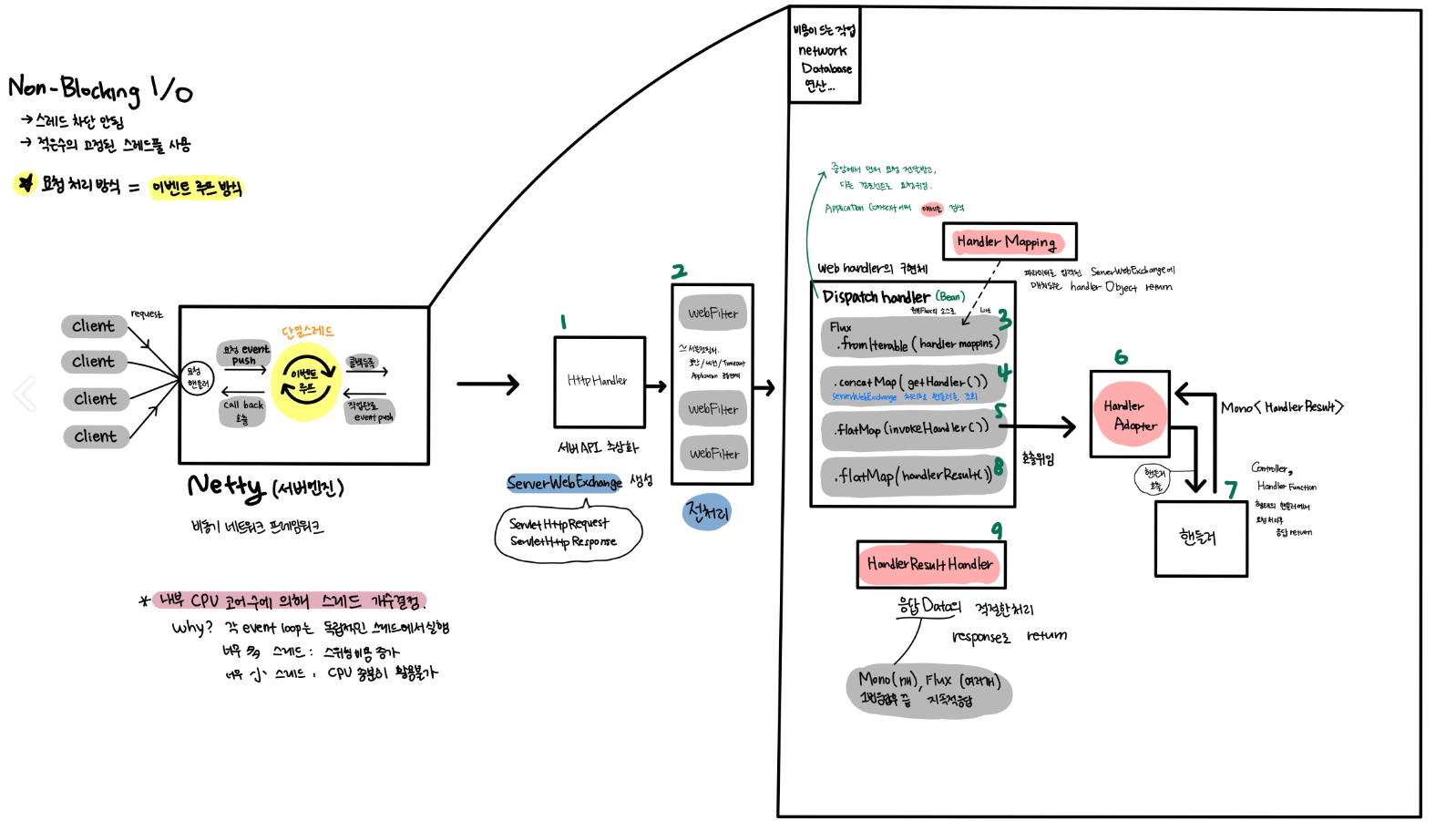
Spring WebFlux의 내부 동작 원리
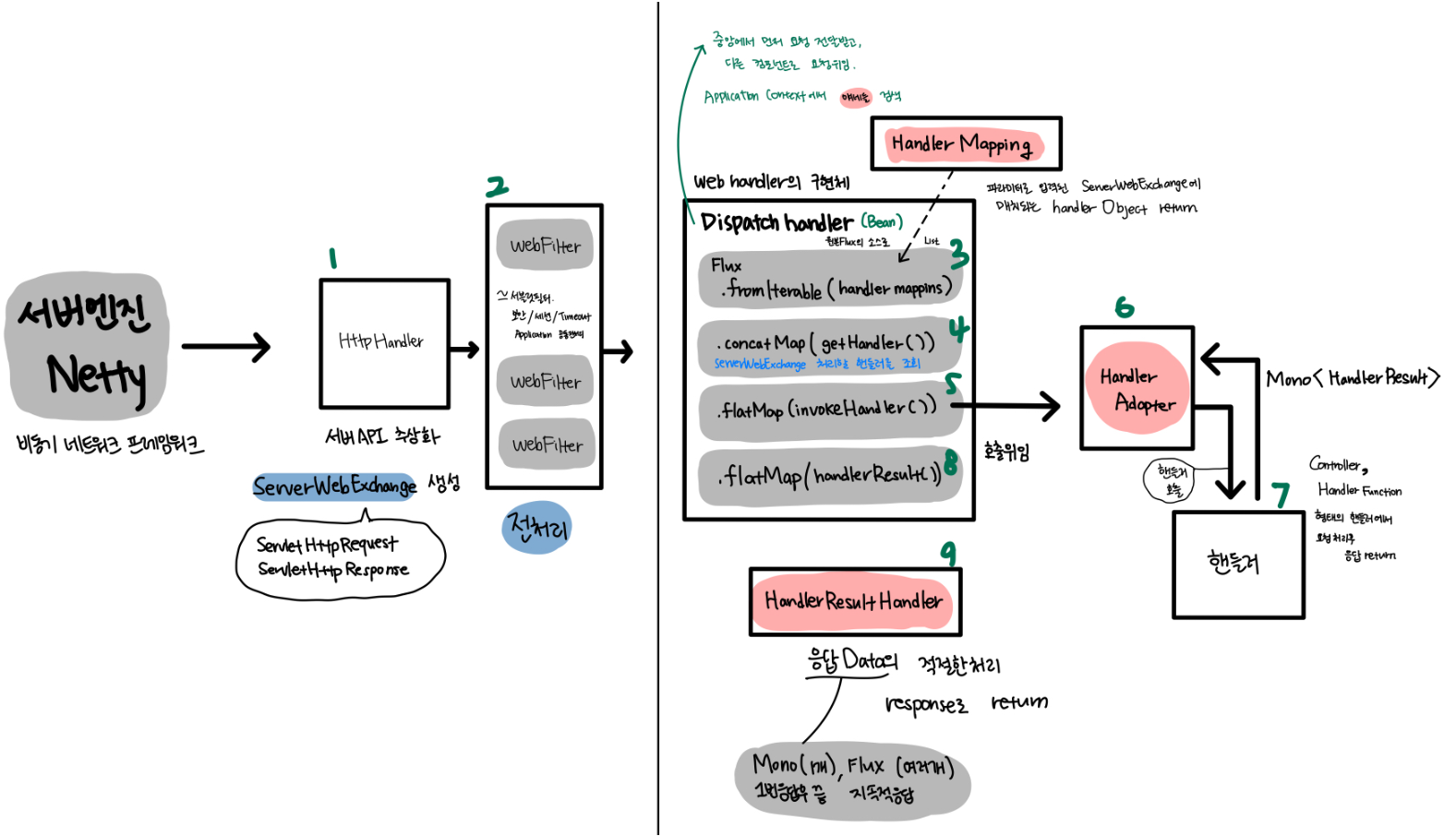
클라이언트의 요청이 발생하면 서버엔진인 Netty를 거치게 된다.
- 1.HttpHandler가 서버 API를 추상화 한다.
Netty 뿐만 아니라 다양한 서버 엔진이 지원된다.
ServerWebExchnage를 생성한다. 이 친구한테 ServletHttpRequest, ServletHttpResponse가 포함된다. - WebFilter
필터 체인으로 구성된 웹 필터이다.
ServerWebExchange의 전처리 과정을 실천한다.
이후 Web handler의 구현체인 Dispatcher Handler에게 전달된다. - DispatchHandler
SpringMVC의 Dispatcher Servlet과 유사한 역할
Handler Mapping에게서 핸들러 매핑 리스트를 받아서, 원본 Flux의 소스로 전달 받는다. - 4.getHandler
ServerWebExchanger를 처리할 핸들러를 조회한다 - 핸들러 어댑터에게
ServerWebExchanger를 처리하도록 위임한다. HandlerAdapter
해들러 어댑터는 핸들러를 호출한다.
이때 호출되는 핸들러의 형태는 Controller, Handler Function 형태이며Mono<HandlerResult>를 반환한다.- 반환받은 응답 데이터를 처리할
HandlerResultHandler를 조회한다. HandlerResultHandler
응답 데이터의 적절한 처리 후 return 한다.
Netty의 역할
- 네티는 서버엔진으로 네트워크 I/O 이벤트에 대한 콜백 함수를 등록하고 관리한다.
- 콜백 함수는 특정 이벤트가 발생할 때 자동으로 호출된다.
- 요청처리 방식을 이벤트 루프 방식으로 사용하였고, 이벤트 루프는 단일 스레드를 사용한다.
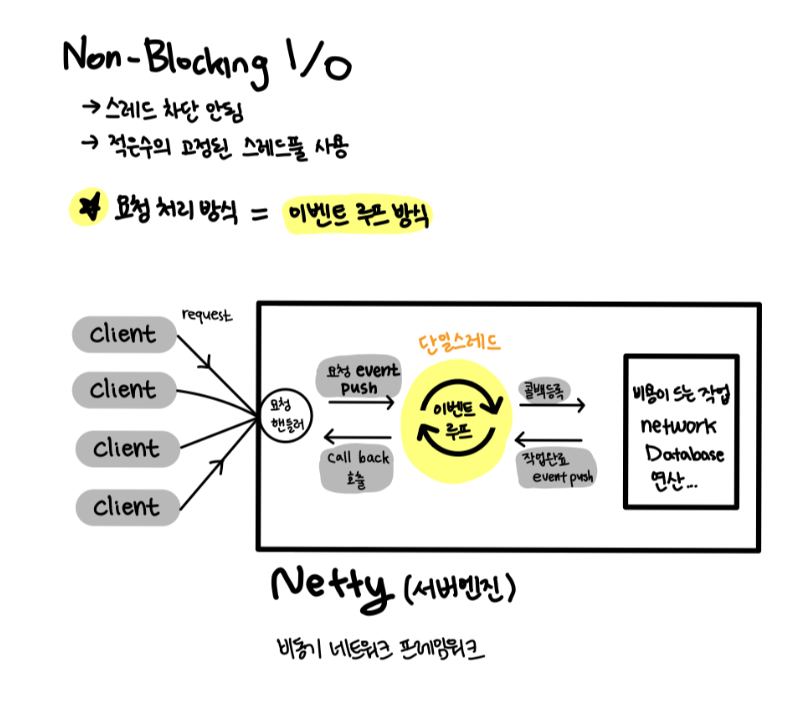
HttpHandler에 가기전 서버엔진에서는 어떤 일이 일어날까?
- 먼저 Client들의 요청은 요청 핸들러를 거친다.
- 요청에 대한 event를 생성하고, 이벤트 루프에 넣는다 (push)
- 이벤트 루프는 (비용이 드는) 작업에 대한 콜백을 등록한다.
- 작업이 완료된 것은 완료 이벤트를 이벤트 루프에 push 한다. 이를 통해 원래 콜백이 실행된다. (콜백이 작업의 결과를 처리한다.)
- 등록된 콜백이 호출해 처리 결과를 전달한다. 결과가 클라이언트에게 반환된다.
스레드의 개수 결정은?
- 내부 CPU 코어 수에 의해 결정 된다.
WHY?
- 각 이벤트 루프는 독립적인 스레드에서 실행되는데
- 이때 너무 많은 스레드는 스레드 스위칭 비용을 증가시키고
- 너무 적은 스레드는 CPU를 충분하게 활용할 수 없기 때문에
- 내부적인 CPU 코어의 수로 결정하도록 설정 되어있다.
728x90
'SpringWebflux' 카테고리의 다른 글
| [SpringWebflux] reactor operator - 4 (0) | 2024.03.08 |
|---|---|
| [SpringWebflux] Reactor operator - 3 (0) | 2024.03.08 |
| [Spring Webflux] CPU bound vs I/O Bound (1) | 2024.03.07 |
| [SpringWebflux] Spring Webflux 소개 (0) | 2024.03.06 |
| [Netty] @Sharable 어노테이션과 ChannelHandler 인스턴스 관리 (0) | 2024.01.10 |


