웹 자동화는 반복적이고 시간이 오래 걸리는 웹 브라우징 작업을 프로그램을 통해 자동으로 수행합니다. 웹 브라우저에서의 데이터 수집, 테스트 자동화, 웹 컨텐츠 관리 등 다양한 분야에서 활용될 수 있습니다.
`Selenium` 은 웹 브라우저의 상호 작용을 자동화하는 데 사용되는 도구로, 사용자가 마치 실제로 웹사이트를 사용하는 것처럼 브라우저를 조작할 수 있게 해줍니다. 예를 들어, 웹사이트의 로그인 프로세스, 폼 제출, 팝업 처리, 다이내믹 콘텐츠 로딩 등 사용자 상호작용을 자동화하여 실제 사용 환경을 시뮬레이션하고 문제를 식별할 수 있습니다.
Selenium 환경 설정
먼저, pip 명령어을 사용하여 Selenium 패키지 를 설치합니다.
pip install selenium이제 다음으로는 웹 브라우저에 맞는 웹 드라이버(Web Driver)를 다운로드합니다. 웹드라이버는 웹 브라우저를 자동화된 방식으로 제어할 수 있게 해주는 소프트웨어입니다.
각각의 웹 브라우저(예를 들어, 크롬, 파이어폭스, 사파리 등)는 각기 다른 웹드라이버를 가지고 있으며, 이들 웹드라이버는 브라우저 제작사에서 제공합니다.
웹 드라이버를 다운로드하는 방법은 크게 3가지입니다.
1) webdriver-manager 이용하기
자동으로 웹 드라이버를 설치하고 업데이트를 관리 해주는 webdriver-manager라는 외부 패키지를 이용하는 것입니다. 셀레니움에 포함되어 있지 않은 외부 패키지이기 때문에 별도로 패키지를 설치해주어야 사용이 가능합니다.
pip install webdriver-manager설치한 webdriver-manager는 파이썬 코드에서 다음과 같이 사용할 수 있습니다. 아래 코드는 셀레니움 4.0 이상의 버전인 경우에 해당합니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.webdriver import WebDriver as ChromeDriver
from webdriver_manager.chrome import ChromeDriverManager
# webdriver_manager를 사용하여 크롬 드라이버의 실행 경로 설정
service = Service(executable_path=ChromeDriverManager().install())
# 설정된 service를 사용하여 크롬 드라이버 인스턴스 생성
driver = ChromeDriver(service=service)
# 테스트하려는 웹사이트 열기
driver.get("http://www.example.com")
# 필요한 작업 수행 후 드라이버 종료
driver.quit()코드는 webdriver-manager가 자동으로 적절한 크롬 드라이버를 다운로드하고, 경로를 설정하여 Selenium이 사용할 수 있도록 해줍니다. 위 코드에서 service 객체는 Selenium 4.0 이상에서 웹드라이버를 관리하는 새로운 방법 중 하나로, 이 객체는 Service 클래스를 사용하여 웹드라이버의 실행을 관리합니다. 여기서 Service 클래스는 웹드라이버의 실행 경로를 지정하는 데 사용되며, 이 경로는 webdriver-manager 라이브러리를 통해 자동으로 설치된 크롬드라이버의 위치로 설정됩니다.
셀레니움 3.x 이하일 경우에는 Service 클래스를 사용하지 않기 때문에 조금 다른 형태로 웹 드라이버의 실행 경로를 지정합니다.
이와 같은 방법을 사용하면 별도로 크롬 드라이버를 관리할 필요 없이 webdriver-manager가 자동으로 웹 브라우저의 버전을 확인하고 OS와 버전에 맞는 웹 드라이버를 다운로드하고 실행합니다. 즉 OS나 크롬 브라우저의 버전이 변경되더라도 소스 코드는 변경 없이 그대로 유지할 수 있습니다.
2) Selenium Manager 이용하기
Selenium Manager도 webdriver-manager 처럼 자동으로 웹드라이버를 관리하는 기능을 제공합니다. 웹드라이버가 필요할 때 자동으로 해당 드라이버를 발견하고, 다운로드하며, 캐시하는 작업을 수행하는데, 일종의 폴백 메커니즘(대체용)으로 작동합니다. 시스템의 PATH에 웹 드라이버가 감지되지 않거나 다른 외부 드라이버 관리 도구가 사용되지 않는 경우에 Selenium Manager가 활성화되어 필요한 웹 드라이버 바이너리를 자동으로 다운로드하고 관리합니다. 이 기능은 새로운 환경을 설정하거나 이미 설치되거나 외부에서 관리되지 않는 특정 버전의 웹 드라이버가 필요할 때 유용합니다. Selenium Manager는 4.6버전 이상의 셀레니움 설치 시 자동으로 함께 포함되기 때문에 별도의 설치 과정은 필요하지 않습니다. 이 기능은 기본적으로 활성화되어 있으며, 특별한 설정 없이도 사용할 수 있습니다.
from selenium import webdriver
# 웹드라이버 자동 관리를 통해 크롬 드라이버 사용
driver = webdriver.Chrome()Seleium Manager가 최신 버전의 셀레니움에 포함되어 있긴 하지만 무조건 해당 매니저 도구를 사용해야하는 것은 아닙니다. 외부 웹 드라이버 관리 도구를 사용하거나 수동으로 직접 드라이버를 관리하는 것도 여전히 가능합니다. 그렇지만 Selenium Manager를 사용하면 더욱 편리하게 웹드라이버를 관리할 수 있으며, 특히 새로운 환경을 설정하거나 특정 버전의 웹드라이버가 필요할 때 자동으로 설치되어 사용할 수 있기 때문에 유용합니다.
3) 수동으로 드라이버 설치하기
마지막으로 수동으로 크롬 드라이버를 설치하는 방법을 알아보겠습니다. 앞에서 살펴본 두 가지 방법이 자동으로 드라이버를 관리해주기 때문에 편하지만 수동으로 드라이버를 설치해야하는 상황이 생길 수 있습니다. 예를 들어, 프로젝트가 특정 버전의 웹드라이버를 요구하고 이 버전이 자동 관리 도구에서 제공하지 않는 경우, 수동 설치가 필요할 수 있습니다. 특히 이전 버전의 브라우저를 지원해야 할 때 이러한 상황이 발생할 수 있습니다.
버전을 확인하기 위해 크롬 브라우저를 실행합니다. 우측 상단의 점 세개(메뉴)를 클릭 → 도움말 → Chrome 정보를 클릭합니다.

Chrome 정보 페이지에서 버전을 확인합니다. 첫번째 나오는 온점(.)의 앞부분, 즉, 가장 앞에 있는 숫자가 크롬의 버전이라고 생각하면 됩니다. 아래의 경우 크롬 버전은 109입니다.

이제 위에서 확인한 크롬 브라우저의 버전에 맞는 크롬 드라이버를 설치합니다. 크롬 드라이버 설치도 동일하게 드라이버 설치 페이지에 접속하여 다운로드하는 방식입니다.
① 직접 아래의 url로 접속
https://chromedriver.chromium.org/downloads
② 포털사이트에서 '크롬 드라이버' or '크롬 드라이버 설치'를 검색하여 드라이버 설치 페이지 접속
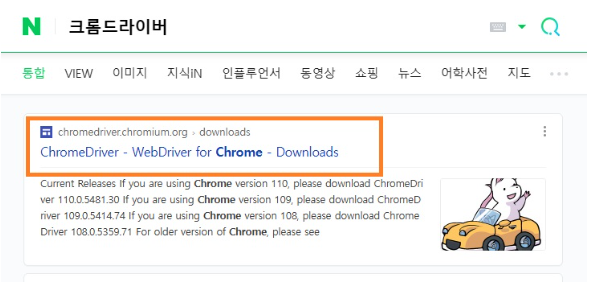
설치된 크롬 브라우저 버전이 최신 버전일 경우 아래와 같이 'Current Release'에 해당 버전의 드라이버를 확인할 수 있습니다. 여기서 바로 확인되는 경우, "Chrome Driver 버전" 부분을 클릭합니다.

만약, 설치된 크롬 브라우저의 버전이 더 낮은 버전이라 여기에 뜨지 않을 경우, 상단의 Downloads 메뉴 → Version Selection 에서 이전 버전 드라이버를 다운 받을 수 있습니다. 그렇지만 설치된 버전이 너무 낮을 경우에는 최신 버전으로 크롬 브라우저를 업데이트할 것을 추천합니다.

드라이버 다운로드 페이지로 이동하면, 아래와 같이 운영체제별로 드라이버를 다운로드 받을 수 있는 창이 떠서 사용하는 운영체제에 맞는 드라이버를 선택하여 다운로드를 진행합니다. 윈도우를 사용하는 경우 x64, x32에 상관없이 win32.zip을 다운로드 합니다.

다운로드 받은 압축파일을 풀어주면 실행 파일인 'chromedriver.exe'가 보이는데, 이 파일을 파이썬 실행 파일이 있는 폴더에 복사해줍니다.
수동으로 설치한 웹 드라이버 파일을 사용할 때는 직접 파일을 시스템의 PATH에 추가할 수도 있고, 아니면 코드에서 파일의 경로를 직접 참조하여 사용할 수 있습니다. 먼저, 웹 드라이버 파일을 시스템 PATH에 추가하면 파이썬 코드를 실행할 때 별도로 경로를 지정해주지 않아도 어디서든 웹드라이버를 찾을 수 있습니다.
윈도우에서 시스템 PATH에 경로를 추가하는 방법은 다음과 같습니다.
① 먼저, 웹드라이버 파일(여기서는 chromedriver.exe)을 원하는 위치에 저장합니다. 예를 들어 C:\drivers 폴더를 만들고 그 안에 파일을 넣습니다. ② 제어판을 열고 '시스템'을 찾은 다음 '고급 시스템 설정'을 클릭합니다. ③ 새로 열린 '시스템' 속성 창에서 상단의 '고급' 메뉴를 클릭한 다음 '환경 변수'를 클릭합니다. ④ 하단의 '시스템 변수' 섹션에서 'Path' 변수를 찾아 '편집'을 클릭합니다. ⑤'새로 만들기'를 클릭하고 저장한 웹드라이버의 경로(C:\drivers)를 입력한 후 '확인'을 클릭해 저장합니다.
이와 같이 시스템 PATH에 웹 드라이버를 추가한 경우, 파이썬에서 셀레니움을 사용할 때 별도의 경로 지정 없이 바로 webdriver.Chrome()을 사용하여 드라이버를 실행할 수 있습니다. 이를 통해 코드를 좀 더 간결하게 만들 수 있고 경로 관련 에러도 방지할 수 있습니다.
from selenium import webdriver
# 시스템PATH의 웹드라이버를 사용하여 드라이버 객체 생성
driver = webdriver.Chrome()
만약 위와 같이 시스템 PATH를 수정하고 싶지 않다면, 파이썬 코드에서 웹드라이버의 정확한 위치를 지정하여 사용할 수 있습니다. 예를 들어, 웹드라이버 파일이 C:\drivers\chromedriver.exe에 위치해 있다면, 셀레니움 스크립트에서 다음과 같이 직접 경로를 지정할 수 있습니다.
from selenium import webdriver
# 웹드라이버 실행 파일의 경로를 지정
chrome_driver = 'C:\\drivers\\chromedriver.exe'
# 웹드라이버 경로를 직접 전달
driver = webdriver.Chrome(chrome_driver)이 방법은 코드가 웹드라이버의 위치를 명확히 알아야 할 때 유용합니다. 시스템 PATH에 추가하는 방법과 경로를 직접 지정하는 방법 중 어느 방법이든, 웹드라이버가 적절히 참조될 수 있도록 환경을 설정하는 것이 중요합니다.
XPath 이해하기
XPath란 웹 문서의 특정 요소나 속성에 접근하는 경로를 지정하는 언어입니다. 실제 웹페이지의 HTML구조는 매우 복잡해서 직접 그 경로를 따라가려면 어려울 수 있지만, XPath를 사용하면 원하는 요소의 정확한 위치를 쉽게 찾을 수 있습니다.
<회사 이름="우리회사">
<본부 이름="A본부">
<팀 이름="1팀">
<직원 직급="부장" 사번"0100">정우성</직원>
<직원 직급="과장" 사번"0150">이지은</직원>
<직원 직급="대리" 사번"0200">차은우</직원>
<직원 직급="사원" 사번"0400">박은빈</직원>
<직원 직급="인턴" 사번"0500">박보영</직원>
</팀>
<팀 이름="2팀"/>
<팀 이름="3팀"/>
...
</본부>
<본부 이름="B본부"/>
...
</회사>
위의 구조에서 직원 "차은우"는 "우리회사" 안의 "A본부" 안의 "1팀"에서 3번째에 위치하고 있습니다. 이를 XPath의 절대 경로로 나타내면, /회사/본부[1]/팀[1]/직원[3]로 표시할 수 있습니다. 이 방식은 문서의 처음부터 시작해 특정 경로를 따라 해당 위치까지 접근합니다.
이렇게 전체 경로를 따라가지 않고 간략하게 표현하고 싶다면, 사번을 이용해 "차은우"의 위치를 가리킬 수도 있을 것입니다. 이 구조에서 사번은 모두 고유한 번호이기 때문에 사번이 "0200"인 직원의 위치를 통해 "차은우"를 찾을 수 있습니다. XPath에는 //[@사번="0200"]으로 표현합니다. 여기서 //는 문서의 어떤 위치에서나 조건에 맞는 요소를 찾을 수 있다는 것을 의미하고, [@사번="0200"]는 사번 속성이 "0200"인 요소를 선택한다는 뜻입니다. 이와 같이 XPath로 /회사/본부/팀/직원[3]이나 //*[@사번="0200"]을 사용해 요소를 찾으면 바로 "차은우"를 선택할 수 있습니다. 웹 페이지에서도 이러한 XPath 식을 사용하여 데이터의 위치를 정확하게 지정하고 추출할 수 있습니다.
(참고) <본부 이름="B본부"/>는 비어 있는 태그인 <본부 이름="B본부">를 축약해 표현한 것입니다. 이는 실제 HTML에서도 자주 사용되는 방식입니다.
XPath 기본규칙
<html>
<head>
<title>업무자동화 공부하기</title>
</head>
<body>
<input type="text" value="아이디를 입력하세요.">
<input type="password">
<input type="button" value="로그인">
<a href="http://naver.com"> 네이버로 이동하기</a>
<div id="content">
<h1 id="title" class="about">웹스크래핑 알아보기</h1>
<p>Beautiful Soup을 공부해보자</p>
</div>
</body>
</html>- 슬래시(/)는 한 단계 아래 요소(element)를 의미합니다.
/html/body/div/h1 - 슬래쉬 두 개(//)는 여러 단계를 생략하여 표시합니다. 이렇게 사용할 경우 하위 모든 요소에 대해 다 찾아보게 됩니다.
//h1[@class='about'] - 별표(*)는 요소의 이름과 상관없이 모든 요소에서 해당 속성을 갖고 있는 요소가 있는지를 찾습니다.
//*[@id="title"]
이 경우, id가 title인 요소를 모든 문서에서 찾게 됩니다.
XPath 확인하기
위의 규칙을 이해했으면 실제 XPath를 확인해봅시다.
브라우저의 개발자 도구에서 간단하게 XPath를 확인할 수 있습니다.

XPath를 찾고자하는 HTML요소에서 마우스 오른쪽 클릭 후,
복사(Copy) → XPath 복사(Copy XPath) 또는, 전체 XPath 복사(Copy full XPath)를 클릭합니다.
XPath 복사(Copy XPath)는 축약된 경로가 표시되고, 전체 XPath 복사(Copy full XPath)는 전체 경로를 다 표시합니다.
'Python' 카테고리의 다른 글
| [Python] UIAutomation for Windows 객체 컨트롤하기 (0) | 2024.10.22 |
|---|---|
| [Python] Selenium으로 웹 브라우저 제어하기 - (1) (0) | 2024.10.18 |
| [Python] 파이썬 리스트 내포(List comprehension) (0) | 2024.09.19 |
| [Python] enumerate() 내장 함수로 for 루프 돌리기 (0) | 2024.09.19 |
| [Python] pprint 로 예쁘게 출력하기 (0) | 2024.09.19 |
