[Spring Webflux] CPU bound vs I/O Bound
CPU란?
CPU란 Computing Process Unit의 약자입니다. 기계어 명령어들을 기반으로 계산을 수행하는 중앙 처리 장치 입니다.
사실 컴퓨터에서 사용되는 대부분의 동작들은 CPU를 사용하게 되는데 CPU Bound 작업이란 단순히 CPU를 사용하는 것이 아닌 CPU를 중점적으로 다루는 작업들을 말합니다.
예를들어 암호화, 압축과 같은 수학적인 알고리즘 계산, 다수의 데이터를 집계하는 작업 등이 있습니다.
주로 CPU 계산 능력에 따라 성능이 좌우되는 그러한 작업들을 말합니다.
CPU Bound

위 그림은 Hardware, Kernel, Application을 계층화, 추상화하여 나타낸 그림입니다. Application 레이어에서는 App #1은 실행된 프로세스이고 물리적인 하나의 CPU코어에 명령을 내리고 있습니다.
만약 단일 CPU 코어 한개에 두개의 작업을 동작시키는 경우에는?

이때 CPU 코어에서는 동시에 실행하는것 처럼 보이지만 동시각대에 하나의 명령만 처리하기 때문에 타임 슬라이스를 아주 잘게 나누어 살펴보면 실제로는 Application 1번과 2번이 결국 번갈아가면서 실행된다고 볼 수 있습니다.
Context switching
이렇게 번갈아가면서 실행하는 과정 자체를 OS에서는 Context switching 이라고 합니다. '실행 관점에서 문맥을 바꿨다'라는 의미입니다. 이러한 Context switching이라는 작업들은 CPU Bound application에서 성능 저하를 가져오게 됩니다.
Application이 실행되어 메모리에 로드되고 프로세스를 동작하게 될텐데, CPU로 스케줄링 되어 실행될때 기계어 실행을 위해 필요한 데이터들을 CPU Register로 미리 가져오게 됩니다. 그리고 ALU를 통해 실제 계산을 진행하게 되는데 Register에는 기존에 어떤 명령까지 진행했는지 함께 저장해놓고 필요에 의해 캐시를 해놓기 때문에 동일한 프로세스의 일을 꾸준히 실행하면 할 수록 성능적으로 더 효과적입니다.
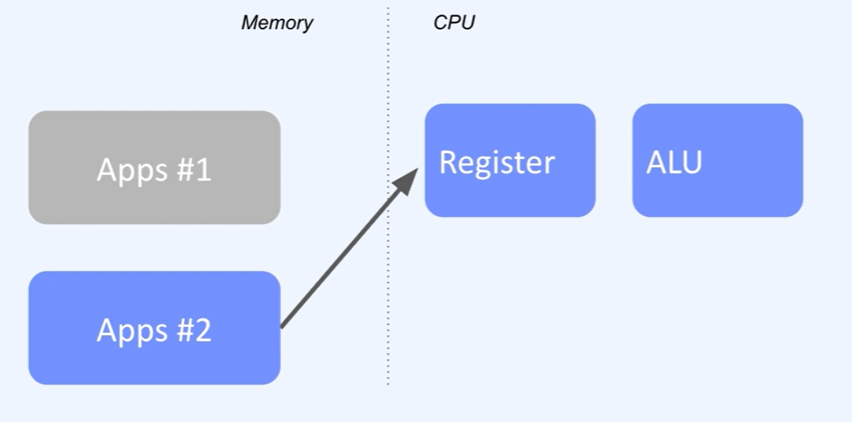
Context switching은 그림에서 보는것과 같이 Application 2번을 실행시키기 위해 Register 정보를 초기화하는 과정부터 시작합니다. 정확히는 1번 Application을 실행했던 기존 실행 정보들을 메모리에 별도로 저장해놓고 2번 Application 데이터 정보를 가져와서 다시 Register에 적재를 한 뒤 명령어들을 실행하게 됩니다.
그래서 하나의 CPU에서 다수의 프로세스들이 번갈아가면서 CPU작업들을 진행해야하기 때문에 성능성 오버헤드가 발생한다고 할 수 있습니다.
현대적인 컴퓨터에선 하나의 CPU를 통해 여러가지 작업, 프로세스를 실행할 수 있도록 설계되어 있기 때문에 이러한 상황들 자체가 매우 정상적으로 동작할 수 있다고 볼 수 있습니다. 그러나 성능 관점에서는 이러한 잦은 Context switching은 적절하다고 볼 수 없습니다.
Q. Application 1번을 실행하고 뒤이어 2번을 실행한 처리 속도와 Application 1번과 2번을 동시에 실행하는 처리 속도 중 어떤게 빠르게 처리 될까요?
위에서 말씀드린 Context switching 오버헤드가 있기 때문에 하나씩 순차적으로 실행하는게 더 빠르게 처리가 됩니다.
Q. 그럼 어떻게 하면 CPU Bound 상황을 효과적으로 만들 수 있을까요?
흔히 말할 수 있는 전략은 다음과 같이 Multi Core CPU를 활용하는 것입니다. 이를 병렬처리 한다고 합니다.
말그대로 동시간대에 2개의 코어에서 명령을 처리 할 수 있도록 합니다. 2개의 CPU작업에서 각각의 코어를 활용함으로써 Context switching 오버헤드를 최소화 할 수 있습니다.


Multi Core의 또다른 배경
Context switching 이 아니더라도 하나의 CPU에 대해 고속화를 하게 되면 특정 지점부터는 발열 문제를 해결하기 어려워 집니다. 일반적으로 CPU를 5Ghz 이상 고속화 하지 않고 Multi Core 방식으로 하드웨어 설계가 발전하게 되었습니다. 평균적으로 3Ghz, 저전력 CPU등을 1Ghz를 활용하는 경우가 많습니다. 서버 하드웨어들은 대략 3-4Ghz를 기반으로 16코어 32코어 64코어를 넘어서 128코어까지 굉장히 많은 코어를 탑재한 경우가 많습니다.
I/O Bound
I/O Bound에서 I/O는 Input, Output의 약자로서 입출력 장치의 중점적인 작업들을 의미합니다. 대표적인 I/O 예시는 키보드에 의한 사용자 입력, 디스크 파일 복사, 네트워크를 통해 데이터를 주고받는 행위를 모두 I/O 작업이라고 할 수 있습니다.
클라이언트는 서버에 연결을 한 상태입니다. Hello라는 문자를 네트워크를 통해 전송을 한다고 가정을 해보겠습니다.

네트워크 인터페이스 카드인 NIC장치는 네트워크 packet을 주고받는 역할을 맡고있습니다. 클라이언트가 전달한 hello packet을 NIC 장치를 통해 전달받고 Kernel에서 네트워크 프로토콜 처리를 진행하게 됩니다.서버 입장에서는 Kernel로 부터 packet을 전달받기 전까지 즉 Kernel에서 packet을 처리하기 전까지 대기를 하게 됩니다.
이제 NIC장치로부터 packet을 받고 Kernel 까지의 과정 또한 CPU 사용이 필요한 영역이긴 하지만, 서버 관점에서는 packet 완료까지 대기하기 때문에 CPU를 중점적으로 사용하지 않는 상태라고 볼 수 있습니다.
만약 packet이 오지 않았다 라고 가정을 한다면 해당 서버의 프로세스는 계속해서 대기를 하게 됩니다.
Web Application 관점에서 I/O Bound
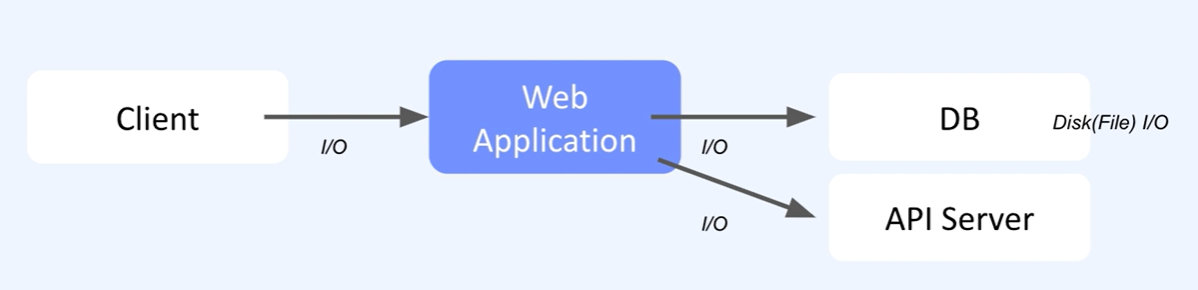
- 클라이언트로 부터 전달받는 HTTP 프로토콜을 처리하는 과정
- 비즈니스 로직 이후 DB 쿼리
- DB시스템에서 데이터를 조회,저장,수정,삭제
- 외부 API 서버에 대한 요청
Q. 클라이언트로 부터 많은 요청이 발생해서 I/O를 동시 처리하게 하려면 어떻게 해야할까요?
전통적인 해결방법은 서버의 Web Application Thread 갯수를 늘리는 것입니다.
Thread per Request 또는 Thread per Connection 라고 부르기도 합니다. 하나의 요청당 하나의 스레드가 필요하다는 의미입니다.

예를들어 굉장히 많은 스레드가 실행된다고 가정을 해보면 성능 관점에서 CPU Context switching을 고려해야 합니다. 이러한 Context switching 오버헤드를 감수하더라도 I/O 요청을 최대한 처리할 수 있는 전략이라고 볼 수 있습니다.
하나의 스레드가 하나의 연결을 처리하고 있는 순간 다른 추가 요청이 있게되면 대기를 하는게 아니라 또 다른 스레드가 처리하게 됩니다.

만약 대량의 요청을 처리하기 위해 요청 수 만큼 스레드 수를 늘리게 된다면 성능과 리소스 관점에서 고려해야 할 상황이 2가지가 있습니다.

- 메모리 용량
스레드를 만들게 되면 메모리가 필요하게 됩니다. 만약 10만 요청을 동시 처리하고 싶다면 메모리 용량(10만 X 스레드크기 ) 이 필요하게 됩니다. 게다가 하드웨어적으로 최대 메모리까지 사용하게 되면 시스템이 아예 동작하지 못할 수도 있습니다.
Kernel 에서는 안전장치인 OOM (Out of Memory)가 있는데요, 주요 프로세스들을 죽임으로써 시스템 다운을 예방하는 장치입니다. 웹어플리케이션까지 말끔하게 정리하게 되버립니다.
- 스레드 생성과 삭제
요청이 완료된 스레드는 삭제하고 새로 들어온 요청을 위해 스레드를 다시 만든다고 생각을 해보면, 스레드를 생성하고 삭제하는 과정자체가 성능 관점에서 손해라고 할 수 있습니다.
ThreadPool

아까 말한 메모리 용량, 스레드 생성과 삭제하는 과정 자체를 해결하는 방법으로서 ThreadPool이 주로 사용됩니다.
가용 가능한 다수의 스레드를 미리 만들어 놓고 요청이 들어오면 미리 만들어 놓은 스레드를 활용하고 사용이 다했으면 해당 스레드를 다시 스레드풀에 반납하는 전략을 말합니다. 즉 OS레벨의 스레드 생성과 삭제를 빈번하게 발생하지 않아 오버헤드를 줄일 수 있고, 시스템 리소스 관점에서 OOM이 동작하는 수준까지 하드웨어적 메모리를 다 쓰는 수준까지 오는것을 예방할 수 있습니다. 물론 Context switching 오버헤드가 발생할 수 있습니다.
Spring MVC 에서 ThreadPool
실제로 spring mvc는 기본 내장된 tomcat에서 ThreadPool 기반으로 동작하게 되어 있습니다.
시작시 최소 스레드갯수와 최대 스레드갯수를 설정하여 관리를 할 수 있습니다. 그래서 특정 최대 스레드갯수만큼 트래픽을 처리할 수 있습니다.
**