Python
[Python Pandas] 엑셀 불러오기 : pd.read_excel
jolocal
2024. 9. 12. 14:59
728x90
Pandas의 read_excel을 이용하면 엑셀 파일을 python의 dataframe으로 불러올 수 있다.
#Pandas
import pandas as pd
Excel 파일 불러오기
pd.read_excel( io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True)
pd.read_excel('경로/불러올파일명.csv')
- 같은 폴더에서 불러올 경우 경로 생략 가능
- 가능한 파일 형식: xls, xlsx, xlsm, xlsb, odf, ods and odt
-
pd.read_excel('경로/파일명.xlsx')
sheet_name : 불러올 시트(Sheet) 지정
- 시트 이름 또는 번호(시작이 0)
-
# 이름으로 불러오기 pd.read_excel('경로/파일명.xlsx', shhet_name = '시트명') # 번호로 불러오기 pd.read_excel('경로/파일명.xlsx', sheet_name = 0)


header: 헤더(열) 지정
- 열 이름(헤더)으로 사용할 행 지정 / 첫 행이 헤더가 아닌 경우 header = None
-
pd.read_excel('파일명.xlsx', header = 1)


names: 열 이름 변경
- 불러오는 열의 개수와 일치해야 한다.
-
pd.read_excel('파일명.xlsx', names=['col1','col2'])

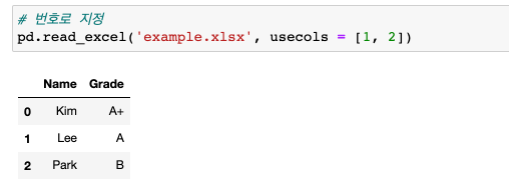
usecols: 불러올 열 지정
-
# 이름으로 지정 pd.read_excel('파일명.xlsx', usecols=['사용할열_1','사용할열_2']) # 번호로 지정 pd.read_excel('파일명.xlsx', usecols=[0,1])

na_values: 결측값 인식하기
- 결측값(NA / NaN)으로 인식 할 문자열 지정
- ', '# N / A', '# N / AN / A', '#NA', '-1. # IND', '-1. # QNAN', '-NaN', '-nan', '1. # IND', '1. # QNAN', '<NA>', 'N / A', 'NA', 'NULL', 'NaN', 'n / a ','nan ','null '는 기본적으로 결측값으로 인식된다.
-
pd.read_excel('파일명.xlsx', na_values = '결측값의_형태')


불러올 행 제한
- nrows: 불러올 행 개수 제한 / 처음 ~n번째 행만 불러오기
- skiprows: 처음 ~n번째 행 제외 / n+1번째 ~ 마지막까지
- skipfooter: 뒤에서 n개 제외
-
pd.read_excel('파일명.xlsx', skiprows = n) # 앞에서 n개 행 생략 pd.read_excel('파일명.xlsx', nrows = n) # 처음~n번째 pd.read_excel('파일명.xlsx', skipfooter = n) #뒤에서 n개 행 생략



728x90