[Java] 멀티플렉싱 기반의 다중 접속 서버로 가기까지
소켓을 통한 네트워크 I/O
소켓은 네트워크에서 서버와 클라이언트, 두 개의 프로세스가 특정 포트를 통해 양방향 통신이 가능하도록 만들어 주는 추상화된 장치입니다. 메모리의 사용자 공간에 존재하는 프로세스(서버, 클라이언트)는 커널 공간에 생성된 소켓을 통해 데이터를 송수신할 수 있다.

소켓은 지역(로컬) IP 주소와 포트 번호, 상대방의 IP 주소와 포트번호, 그리고 수신버퍼와 송신 버퍼가 존재한다.
서버와 클라이언트 소켓이 서로 연결된 후 데이터가 들어오면 수신 버퍼에 수신 데이터가 쓰이고, 반대로 데이터를 내보낼 때는 송신 버퍼에 데이터가 쓰인다.
고찰
서버와 클라이언트 소켓 생성과 연결 과정은 다음과 같습니다.

| 서버 |
|
| 클라이언트 |
|
하나의 클라이언트가 연결할 때는 문제가 없지만 다수의 클라이언트가 연결하는 경우에는 문제가 발생합니다. 처음 연결한 클라이언트가 연결을 종료하기 전까지는 다른 클라이언트의 연결은 listen 큐에 들어가 대기해야 하기 때문입니다. 따라서 다수의 요청을 처리할 수 없다는 문제가 있습니다.
이 문제를 해결하려면 둘 이상의 클라이언트가 동시에 접속해 서버의 서비스를 제공받을 수 있도록 '다중 접속 서버'를 구현해야 하고, 다중 접속 서버는 다음과 같이 여러 가지 방법으로 구현할 수 있습니다.
- 멀티프로세싱(multiprocessing) 기반 서버: '프로세스를 다수 생성'하는 방식으로 서비스를 제공한다.
- 멀티스레딩(multithreading) 기반 서버: '스레드를 다수 생성'하는 방식으로 서비스를 제공한다.
- 멀티플렉싱(multiplexing) 기반 서버: '입출력 대상을 묶어서 관리'하는 방식으로 서비스를 제공한다.
멀티프로세싱 기반 다중 접속
멀티프로세싱 기반의 다중 접속 서버는 다수의 프로세스를 생성하는 방식으로 서비스를 제공합니다.

- 메인 스레드는 리스닝 소켓으로 accept 함수를 호출해서 연결 요청을 수락한다.
- 이때 얻는 소켓의 파일 디스크립터(클라이언트와 연결된 연결 소켓)를 별도 워커 스레드를 생성해 넘겨준다.
- 워커 스레드는 전달받은 파일 디스크립터를 바탕으로 서비스를 제공한다.
핵심은 연결이 하나 생성될 때마다 프로세스가 아닌 스레드를 생성해서 해당 클라이언트에게 서비스를 제공하는 것입니다.
고찰
| 장점 |
|
| 단점 |
|
각 클라이언트 요청마다 별도의 스레드를 생성함으로써 프로세스를 생성하던 방법보다 리소스 비용을 줄일 수 있었고, 스레드가 서로 공유하는 메모리를 가질 수 있는 환경이 됐습니다. 여기서 더 나아가 I/O 멀티플렉싱(Multiplexing)기법을 사용한다면, 각 클라이언트마다 별도 스레드를 이용하는게 아니라, 하나의 스레드에서 다수의 클라이언트에 연결된 소켓(파일 디스크럽터)을 관리하면서 소켓에 이벤트(read/write)가 발생할 때만 해당 이벤트를 처리하도록 구현함으로써 더 적은 리소스를 사용하도록 개선할 수 있습니다.
멀티플렉싱 기반의 다중 접속 서버
'입출력 다중화'란 하나의 프로세스 혹은 스레드에서 입력과 출력을 모두 다룰 수 있는 기술을 말합니다. 커널(Kernel)에서는 하나의 스레드가 여러 개의 소켓(파일)을 핸들링 할 수 있는 select, poll, epoll, io_uring 과 같은 시스템 콜(System call)을 제공하고 있습니다. 그럼에도 지금까지 하나의 프로세스나 스레드에서 하나의 클라이언트에 대한 입출력만 처리할 수 있었던 이유는, 입출력 함수가 블록되면 입출력 데이터가 준비될 때까지 무한정 블록돼 여러 클라이언트의 입출력을 처리할 수 없었기 때문입니다.
I/O 멀티플렉싱 기법을 사용하면, 비록 입출력 다중화에서도 입출력 함수 자체는 여전히 블록하는 것으로 작동하지만, 입출력 함수를 호출하기 전에 어떤 파일에서 입출력이 준비됐는지를 확인할 수 있습니다.
이와 같은 블로킹 I/O가 무엇인지 이해하기 위해 먼저 짚고 넘어가야 할 두 가지 사항이 있습니다.
- 애플리케이션에 I/O 작업을 할때, 스레드는 데이터가 사용할 수 있는 상태로 준비될 때까지 대기합니다. 예를 들어 소켓을 통해 READ를 수행하는 경우 데이터가 네트워크를 통해 도착할 때까지 기다립니다. 패킷이 네트워크를통해 도착하면 커널 내 버퍼에 복사됩니다.
- 커널 내 버퍼에 복사된 데이터를 애플리케이션에서 사용하기 위해서는 커널 공간(Kernel space)에서 사용자 공간(user space)으로 복사해야 합니다. 애플리케이션은 사용자 모드에서 사용자 공간에만 접근할 수 있기 때문입니다.
블로킹 I/O 모델
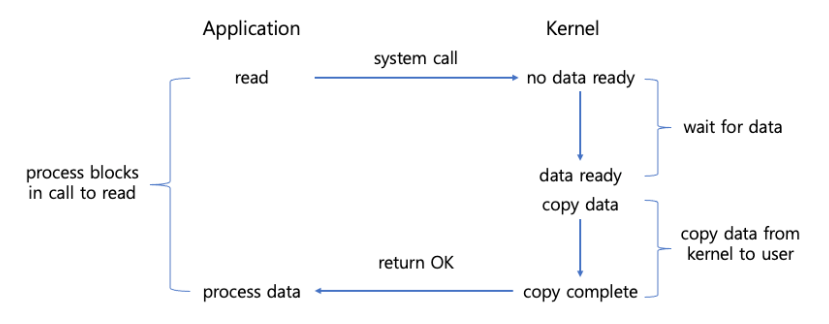
READ 함수는 커널 공간에 데이터가 도착하길 기다리는 것부터 시작하기 때문에, 프로세스(스레드)가 하나의 소켓에 대해 READ함수를 호출하면, 데이터가 네트워크를 통해 커널 공간에 도착해 사용자 공간의 프로세스 버퍼에 복사될 때까지 시스템 콜이 반환되지 않습니다.
I/O 멀티플렉싱 모델

멀티플렉싱 모델에서는 SELECT 함수를 호출해서 여러 개의 소켓 중 READ 함수 호출이 가능한 소켓이 생길 때 까지 대기합니다. SELECT의 결과로 READ 함수를 호출할 수 있는 소켓의 목록이 반환되면, 해당 소켓들에 대해 READ 함수를 호출합니다.
블로킹 I/O 모델은 하나의 스레드에서 하나의 소켓에 대해 READ 함수를 호출해 데이터가 커널 공간에 도착했는지 확인하고 현재 읽을 수 있는 데이터가 없는 경우 블록돼 대기했다면, 멀티플렉싱 I/O 모델은 여러 소켓을 동시에 확인하며 그중 하나 이상의 사용 가능한 소켓이 준비될 때까지 대기합니다.
select
select 방식은 이벤트(입력, 출력, 에러)별로 감시할 파일들을 fd_set이라는 파일 상태 테이블(파일 디스크립터 비트 배열)에 등록하고, 등록된 파일(파일 디스크립터)에 이벤트가 발생하면 fd_set을 확인하는 방식으로 작동합니다.

예를 들어 위와 같이 6개의 파일을 다뤄야 할 때, 6개의 파일에 대해 입출력 데이터가 준비될 때까지 이벤트를 기다리는 파일 상태 테이블을 준비합니다. 그 후 6개의 파일 중 입출력이 준비된 파일에 대한 이벤트가 발생하면 이벤트가 발생한 파일 디스크립터의 수를 반환합니다. 이후 이벤트가 준비된 파일에 대해 입출력을 수행하는데, 이미 데이터가 준비된 파일에 대해 입출력을 수행하기 때문에 무한정 대기해야 하는 블록이 발생하지 않을 것이라는 게 보장됩니다
각 클라이언트 요청마다 별도 프로세스나 스레드를 할당해서 처리하는 게 아니라 하나의 프로세스(스레드)에서 여러 입출력을 관리함으로써 문제를 해결했습니다.
고찰
| 장점 |
|
| 단점 |
|
poll
poll도 select와 마찬가지로 멀티플렉싱을 구현하는 시스템 콜입니다. poll이 여러 개의 파일을 다루는 방법은 select와 같습니다. 파일 디스크립터의 이벤트를 기다리다가 이벤트가 발생하면, poll에서의 블록이 해제되고 어떤 파일 디스크립터에 이벤트가 발생했는지 검사하는 방식입니다. poll의 작동 원리는 select와 비슷하므로 생략하고, select와 비교한 차이점에 대해서만 간단히 정리하겠습니다.
| 장점 |
|
| 단점 |
|
epoll
epoll은 select와 poll의 단점을 해결할 수 있는 멀티플렉싱을 지원합니다. 커널에 관찰 대상에 대한 정보를 한 번만 전달하고, 관찰 대상의 범위나 내용에 변경이 있을 때에만 변경 사항을 알려줍니다. 비슷한 역할을 하는 시스템 콜로 Windows에는 IOCP, FreeBSD에서는 Kqueue가 있습니다.
epoll 역시 작동 원리를 설명하는 대신 select와 poll과 비교한 차이점에 대해서만 알아보겠습니다.
| 장점 |
|
| 단점 |
|